Four different I/O & Data Flow releated technical challenges are targeted within EoCoE-II:
Improvement of I/O accessibility: Different I/O libraries support a variety of different configuration options. Depending on the situation these options must be continually updated, or a complete new library must be adapted. We want to introduce a generic interface with the help of the Portable Data Interface (PDI), which decouples the I/O API and the application to allow easier switching between different I/O subsystems. These interface should either serve standard I/O operation but should also be useful in context of ensemble or in-situ visualisation data movement.
I/O performance: The data writing and reading time can consume a significant part of the overall application runtime and should be minimized. For this we want to leverage the optimization options of different I/O libraries in use as well by adapting intermediate storage elements such as flash storage devices.
Resiliency: Running an application on a large scale increases the chance of hard- or software problems if more and more computing elements are involved in the calculation. Additional I/O techniques can be used to reduce the effort needed to restart a broken run or even avoid an overall crash, by storing intermediate snapshots to the storage elements. In particular we want to focus on resiliency for ensemble calculations.
Data size reduction: Running an application on a larger scale often implies an increasing data size, which can become unmanageable and consume too much resources. Within this task we want to reduce the overall data size without losing necessary information via in-situ and in-transit processing, moving post-processing elements directly into the frame of the running application.
PDI
PDI (Portable Data Interface) supports loose coupling of simulation codes with libraries:
- the simulation code is annotated in a library-agnostic way,
- libraries are used from the specification tree.
This approach works well for a number of concerns including: parameters reading, data initialization, post-processing, result storage to disk, visualization, fault tolerance, logging, inclusion as part of code-coupling, inclusion as part of an ensemble run, etc.
Within EoCoE II PDI is used as the main data exchange interface either for classical I/O, visualisation or ensemble data handling.
See more: https://pdi.dev/master/
SIONlib
SIONlib is a library for writing and reading data from several thousands of parallel tasks into/from one or a small number of physical files. Only the open and close functions are collective while file access can be performed independently.
SIONlib can be used as a replacement for standard I/O APIs (e.g. POSIX) that are used to access distinct files from every parallel process. SIONlib will bundle the data into one or few files in a coordinated fashion in order to sidestep sequentialising mechanism in the file system. At the same time, the task-per-file picture is maintained for the application, every process has access to its logical file only.
See more: http://www.fz-juelich.de/jsc/sionlib
FTI
FTI stands for Fault Tolerance Interface and is a library that aims to give computational scientists the means to perform fast and efficient multilevel checkpointing in large scale supercomputers. FTI leverages local storage plus data replication and erasure codes to provide several levels of reliability and performance. FTI is application-level checkpointing and allows users to select which datasets needs to be protected, in order to improve efficiency and avoid wasting space, time and energy. In addition, it offers a direct data interface so that users do not need to deal with files and/or directory names. All metadata is managed by FTI in a transparent fashion for the user. If desired, users can dedicate one process per node to overlap fault tolerance workload and scientific computation, so that post-checkpoint tasks are executed asynchronously.
See more: https://github.com/leobago/fti
IME
The Infinite Memory Engine (IME), as designed by partner DDN, one of the main storage technologies used successfully in HPC setups today. IME is a layered hybrid approach, where the capacity file system is extended by a layer of low-latency devices to cope with response time requirements. DDN IME originates from HPC applications and architectures, where
I/O has been carefully co- designed over many years, yielding to an eco-system where the hardware is enhanced with complex middleware to meet application requirements.
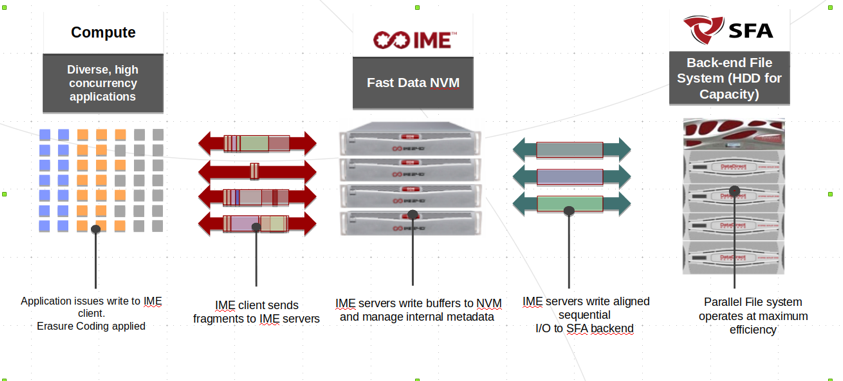
Applications have two possible data path to access to the IME client, either the Fuse interface (expose as a traditional mount point) or directly using the IME Native interface. The former offering compliance and ease of access and the later the extreme level of performance. Once of the technical milestone of EoCoE II is to interface the SIONlib middleware directly with the IME Native Interface.
See more: https://www.ddn.com/products/ime-flash-native-data-cache/
Data Interface
Along the project, the PDI team has worked on the improvement of the PDI Data Interface in many ways. In addition to the improvement of PDI itself, the team has worked in close collaboration with simulation code developers to integrate and leverage the library in their applications: Alya, ESIAS, Gysela, Parflow, SHEMAT-Suite, …
A new much-improved website has been deployed (https://pdi.dev/), with access to hands-on tutorial, user and reference documentation as well as developer documentation. Packages are now offered to ease installation on Debian, Fedora, Ubuntu, and Spack in addition to the still available source distribution. The library is tested with about thousand of distinct tests on more that 20 architectures to ensure the production-grade quality.
PDI team is proud to have generated more than 30 releases of the library along EoCoE-2, each improving on the previous one.
Improved API
PDI integration in simulation codes has been made easier by improving its type system to match the requirements of its users. Support for new types makes it easy to integrate and inter-operate between C, C++, Fortran or python codes. A type annotation system has been developed that makes it possible to expose data to PDI without having to specify its layout. A dedicated compiler generates PDI data layout information from C code directly.
Additional back-ends
New plugins have been developed to extend the range of actions possible with the data exposed to PDI. A Decl’NetCDF back-end has been developed with support for both the sequential and parallel versions of NetCDF library. The plugin YAML configuration has been designed to be as close as possible to that of Decl’HDF5 hence making the switch from one to the other easy. This plugin leverages PDI new type annotation system developed in the scope of EoCoE to make integration seamless.
A plugin dedicated to the FlowVR framework is now part of PDI distribution. A plugin dedicated to the Melissa framework developed in the project is also developed. This plugin is developed along the Melissa framework itself and a final stable release is expected at the end of EoCoE-2.
Existing back-ends have also been updated and improved with new performance options available in Decl’HDF5. The Decl’SION and FTI plugins are also kept up-to-date to ensure long term support of our users.
In situ data manipulation capabilities
In addition to input and output to disk, PDI has seen huge improvement to its support for in situ data manipulation. PDI now offers direct support for data manipulation from YAML directly in the application process. In addition to its dedicated language, this can be done in python, C, C++ or Fortran.
In addition to the FlowVR and Melissa plugins mentioned previously, two plugins specifically targeted at in situ data analysis support have been developed and tested.
A plugin dedicated to SENSEI usage has been developed. This plugin has been used to interface the Alya simulation code with ADIOS-2 and SENSEI for in situ visualisation at scale[1], see below for more details.
Another plugin has been developed to target Dask. This plugin has been split in a Dask in situ analytics extension: Deisa and an associated PDI plugin. This approach has been used to execute heavy analysis in situ along the execution of the Gysela code with close to no impact on the simulation code or sequential python analytics[2].
[1] Christian Witzler, J. Miguel Zavala-Aké, Karol Sierocinski, and Herbert Owen. Including in situ visualization and analysis in pdi. In Heike Jagode, Hartwig Anzt, Hatem Ltaief, and Piotr Luszczek, editors, High Performance Computing, pages 508–512, Cham, 2021. Springer International Publishing.
[2] Amal Gueroudji, Julien Bigot, and Bruno Raffin. Deisa: dask-enabled in situ analytics. In HiPC 2021 – 28th International Conference on High Performance Computing, Data, and Analytics, pages 1–10, virtual, India, December 2021. IEEE.
Checkpointing in Ensemble Data Assimilation
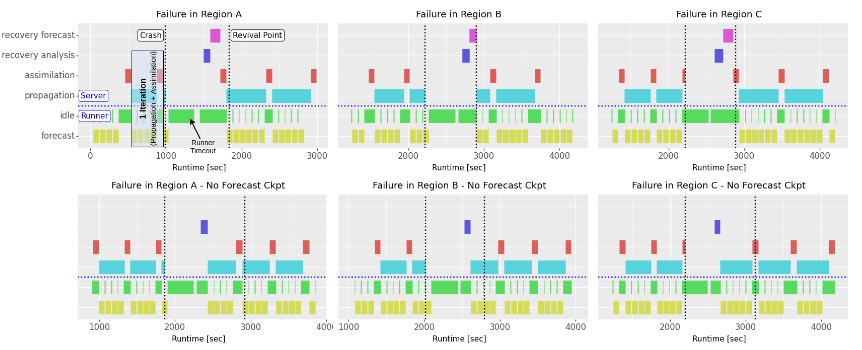
As part of the EoCoE2 effort on improving I/O for a range of different use cases, we have designed and developed an effortless framework protection leveraging checkpoint/restart. The checkpoints fulfill the purpose of resiliency and hold the climate model results in form of shared HDF5 checkpoint files. The files contain both the background and analysis states of the data assimilation ensemble runs. We use dedicated threads and MPI processes to overlap the checkpoint creation with the framework execution. We demonstrate that the overhead is effectively hidden behind the framework’s normal operation (zero-overhead checkpoint). Our implementation manages further to recover from failures with none or few recomputation (zero-waste recovery). In addition, we derive a model that predicts the average cost of failures during continuous operation.
[3] HiPC 2021: Keller, Kai, Adrian Cristal Kestelman, and Leonardo Bautista-Gomez. “Towards Zero-Waste Recovery and Zero-Overhead Checkpointing in Ensemble Data Assimilation.” 2021 IEEE 28th International Conference on High Performance Computing, Data, and Analytics (HiPC). IEEE, 2021.
[4] HiPC 2020: Keller, Kai, Konstantinos Parasyris, and Leonardo Bautista-Gomez. “Design and Study of Elastic Recovery in HPC Applications.” 2020 IEEE 27th International Conference on High Performance Computing, Data, and Analytics (HiPC). IEEE, 2020.
In situ visualization
In situ visualization is a tool that allows us to visualize simulation data directly without having to store the data. Since the hard disk performance increases slower than the computational power, in-situ visualization can generate images with high temporal and spatial resolution. These then require significantly less storage space than storing the entire dataset. This will not replace saving the entire dataset in most cases, because it is essentially a very specific non reversible data compression.
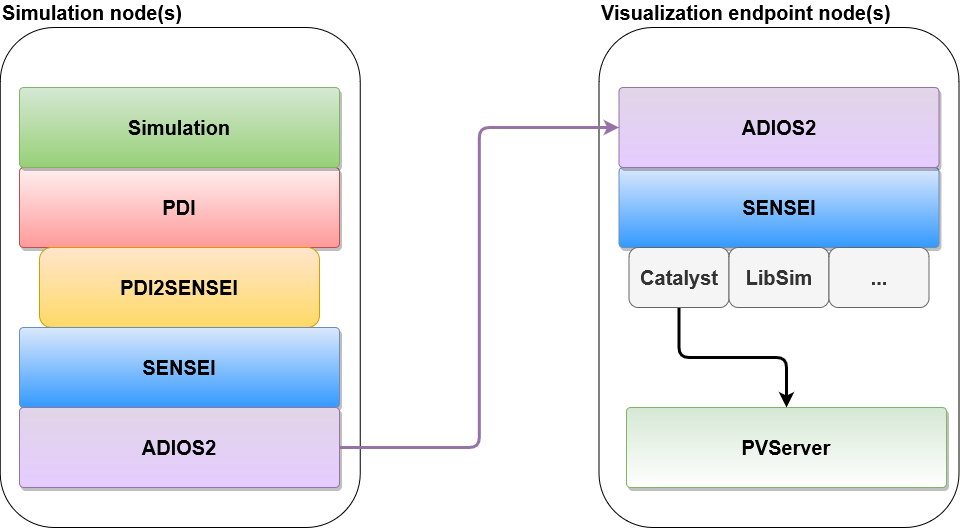
To enable simulations to integrate in-situ visualization we are using multiple dependencies, that are used in concert while hiding the complexity from the simulation. As the entry layer from the simulation we are using PDI, this allows a unified entry for in-situ and normal IO operations. As a next step pdi2sensei is used, to facilitate an easy setup of the in-situ pipeline, that is visible in the figure below. There you can see that the normal setup uses a divided setup, one part for the simulation and the other one for the data processing.
This needs a data transport, which uses ADIOS2 as a transport layer, and allows the special in-situ case that is called in-transit, therefore data is transported to different nodes, to decrease the effect the visualization has on the running simulation.
As a middle layer that inputs data and extracts it from ADIOS2 we are using SENSEI, which allows to link to multiple different in-situ frameworks and change the targets with small configuration changes. Therefore, this keeps the flexibility to choose a different data transport later on. In case of the visualization nodes we need this flexibility as well, to allow users a choice for the framework they feel most comfortable with for the actual data visualization.
The approach used here is to use Catalyst, which is the in-situ library provided and linked to ParaView. This allows to run predefined visualization scripts and connect it to an interactive GUI to see live results of your data and try out new visualizations while getting new data delivered and update the actual visualization.
The described approach was used for two of the EoCoE-II codes, namely in ALYA and ParFlow.
Flash storage evaluation
Besides pure software-based approaches to optimize the I/O capabilities of a certain application, we also analysed the impact of new types of storage devices Infinite Memory Engine (IME) technology by DDN to act as an intermediate cache device between the application and the underlying hardware.
As a testbed, we used the newly released High-Performance Storage Tier (HPST) system at JSC, which is built on top of IME technology and allowed us to be one of the first users to utilize and evaluate this new system of the centre.
To allow us to have a direct comparison we utilize an older version of the Gysela fusion application, which also offered the capabilities to use either a standard HDF5 task-local backend or a SIONlib based backed. Using SIONlib allowed us to also implement the IME native API underneath to evaluate also the utilization of this particular software backend in contrast to the regular FUSE mount based POSIX approach [5].
A weak scaling test, performed on JUWELS in a direct comparison between the HPST and the regular Spectrum Scale based parallel file system highlighted the clear benefit of having an intermediate cache layer. Utilizing the native API underneath of SIONlib slightly improved the bandwidth on smaller scales, where the individual client performance limits the overall bandwidth, while on larger scales the bandwidth is limited by the overall system and the server architecture.
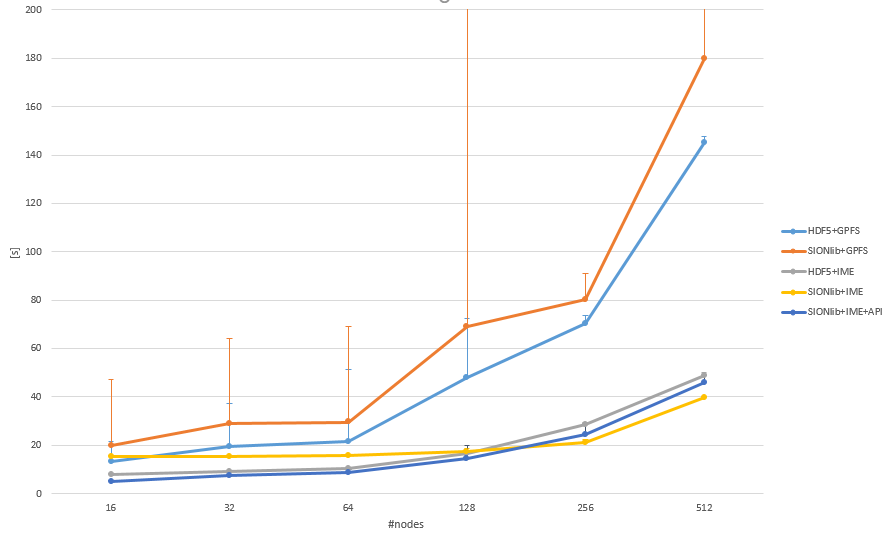
[5] Konstantinos Chasapis, Jean-Thomas Acquaviva, Sebastian Lührs “Integration of Parallel I/O Library and Flash Native Accelerators: An Evaluation of SIONlib with IME” CHEOPS ’21 10.1145/3439839.3458736
All the EoCoE-I and EoCoE-II publications are available here (openAIRE).